Projects
Real-time Drone Fleet Monitoring System
Built a real-time monitoring system for autonomous drone fleets that tracks battery levels, altitude, speed, and proximity to restricted zones. The system provides early warnings (~10-12 sec latency) when drones approach restricted areas, monitors live drone status, and identifies potential hardware issues in real-time through an interactive dashboard.
- Apache Kafka
- Apache Flink
- Astra DB
- PostgreSQL
- Protocol Buffers
- Plotly
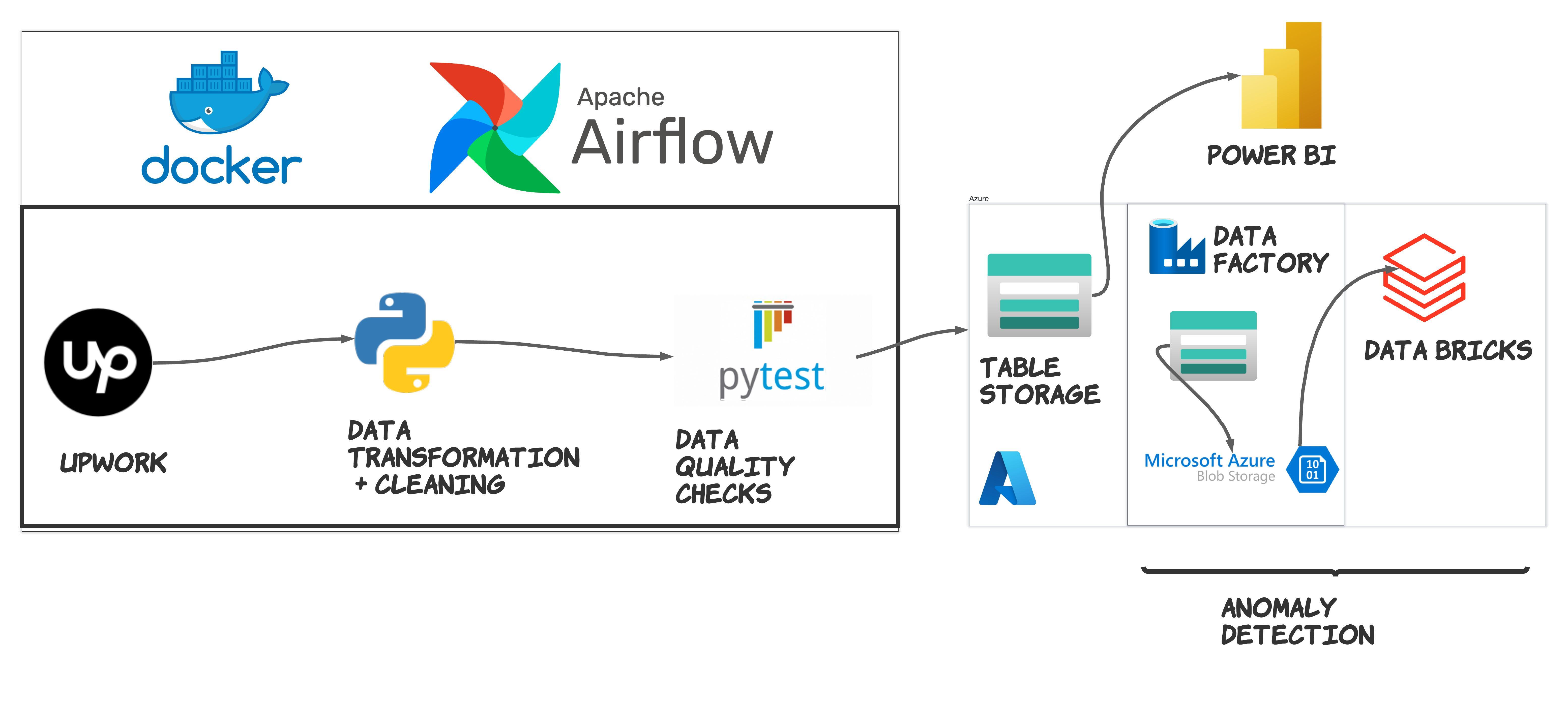
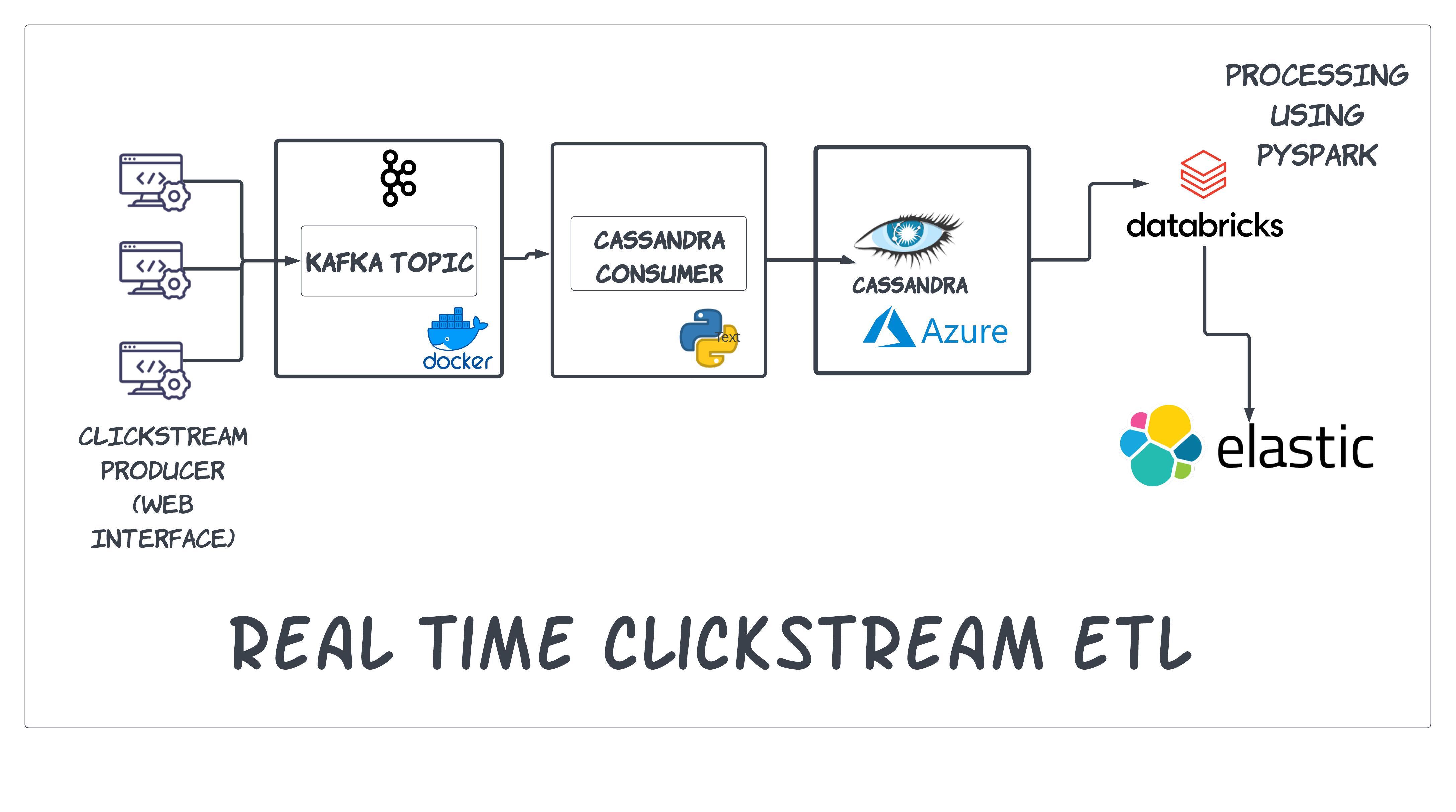
RealtimeClickStreamETL
Clickstream ETL (Extract, Transform, Load) pipeline designed to consume real-time data from a Kafka and Zookeeper cluster. The pipeline utilizes Python for initial data processing and enrichment before storing the raw clickstream data in Apache Cassandra. The raw data in Cassandra is then processed and enriched using PySpark on Databricks to perform complex transformations. Finally, the processed data is stored in Elasticsearch for efficient querying and analysis.
- Python
- Docker
- Azure Databricks (Pyspark)
- Apache Cassandra
- Elasticsearch
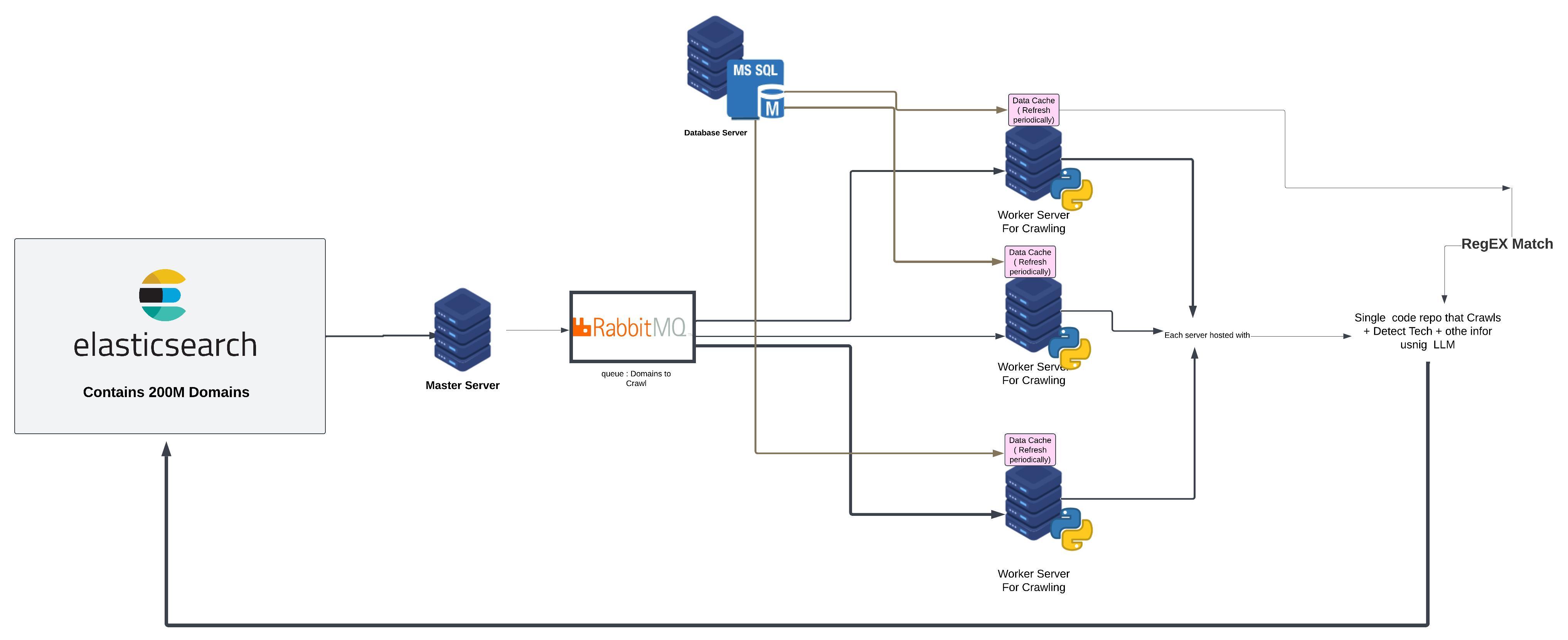
Tech Detector
A distributed system that detects and analyzes technologies used across 200M+ domains. Utilizes Playwright for HTML extraction through proxies, along with predefined patterns and regex matching to identify web technologies. Built with Python and RabbitMQ for distributed processing across multiple servers.
- Python
- Playwright
- RabbitMQ
- Elasticsearch
